Overview of the working principles of LLMs#
In this notebook, we have compiled a list of valuable resources to help you understand how Large Language Models (LLMs) work. Here, you will find accessible explanations of the fundamental principles behind these models.
💻 Online resources#
Transformers#
Transformers have become the leading architecture for solving natural language processing (NLP) tasks, enabling the development of powerful language models. Introduced in the groundbreaking 2017 paper “Attention Is All You Need” by Google researchers, the Transformer architecture has transformed the field of NLP. To understand the fundamentals of Transformers, you can explore the resources shown below. (Figure - The Transformer, model architecture. Source: “Attention Is All You Need” paper)
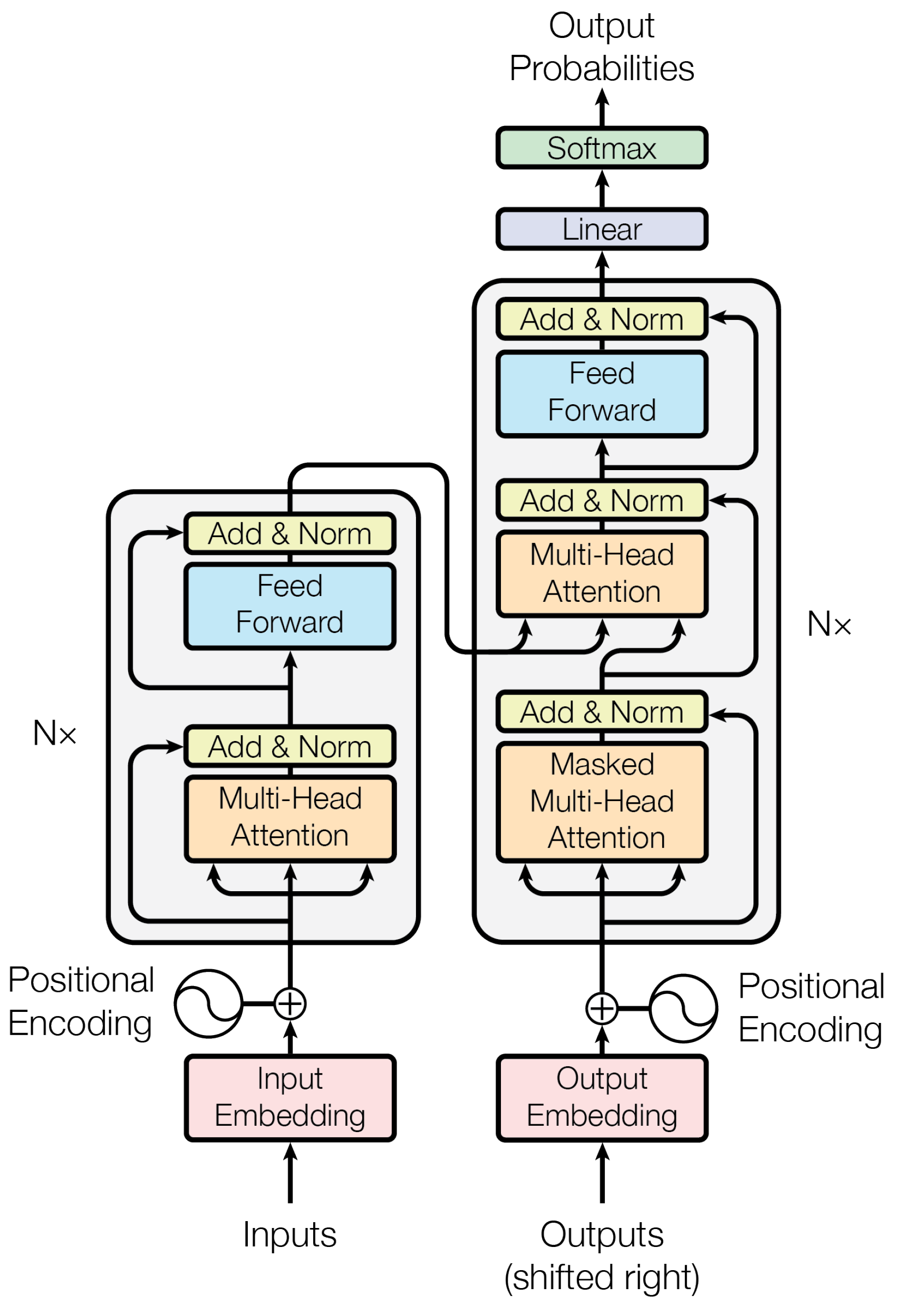
-
This post from Harvard University presents an annotated version of the paper “Attention is All You Need” in the form of a line-by-line implementation. It reorders and deletes some sections from the original paper and adds comments throughout. Thus, it explains the model architecture (Transformer), model training, and a real-world example. This document is a notebook that allows a completely usable implementation.
Understanding the Transformer architecture for neural networks
In this article, Jeremy Jordan explains the Transformer architecture with a focus on the attention mechanism, encoder, decoder, and embeddings. His didactic approach is enriched with many explanatory schemas, making the concepts easy to understand.
-
In this post, Jay Alammar demystifies how Transformers work. He simplifies complex concepts like encoders, decoders, embeddings, self-attention mechanisms, and model training by explaining each one individually, using numerous schemas to enhance understanding.
The Transformer architecture of GPT models
This article by Bea Stollnitz explains the architecture of GPT models, which are built using a subset of the original Transformer architecture. It shows a GPT-like version of the code that can be compared with the original Transformer to understand the differences.
A walkthrough of transformer architecture code
This notebook, designed for illustration and didactic purposes, provides a comprehensive walkthrough of the Transformer architecture code. It guides you through a single forward pass, explaining each stage of the architecture with the help of a detailed computation graph.
-
Here, Brendan Bycroft shows an impressive interactive visualization of the LLM algorithm behind some of OpenAI GPT models, allowing you to see the entire process in action.
🎥 You can also find a clear explanation of Transformers in the video The Transformer Architecture by Sebastian Raschka.
Attention#
The concept of “attention” in deep learning emerged from the need to improve recurrent neural networks (RNNs) for handling longer sequences. Working word-by-word is not effective. To overcome this issue, attention mechanisms were introduced to give access to all sequence elements at each time step. The key is to select and determine which words are most important in a specific context. The transformer architecture uses an autonomous self-attenuation mechanism that solves the problem of accessing the entire sequence in constant time. To understand the attention mechanisms, you can explore the resources shown below. (Figure - Computing the attention scores to weigh the importance of different elements in an input sequence. Source: “Understanding and Coding the Self-Attention Mechanism of Large Language Models From Scratch” post by S. Raschka)
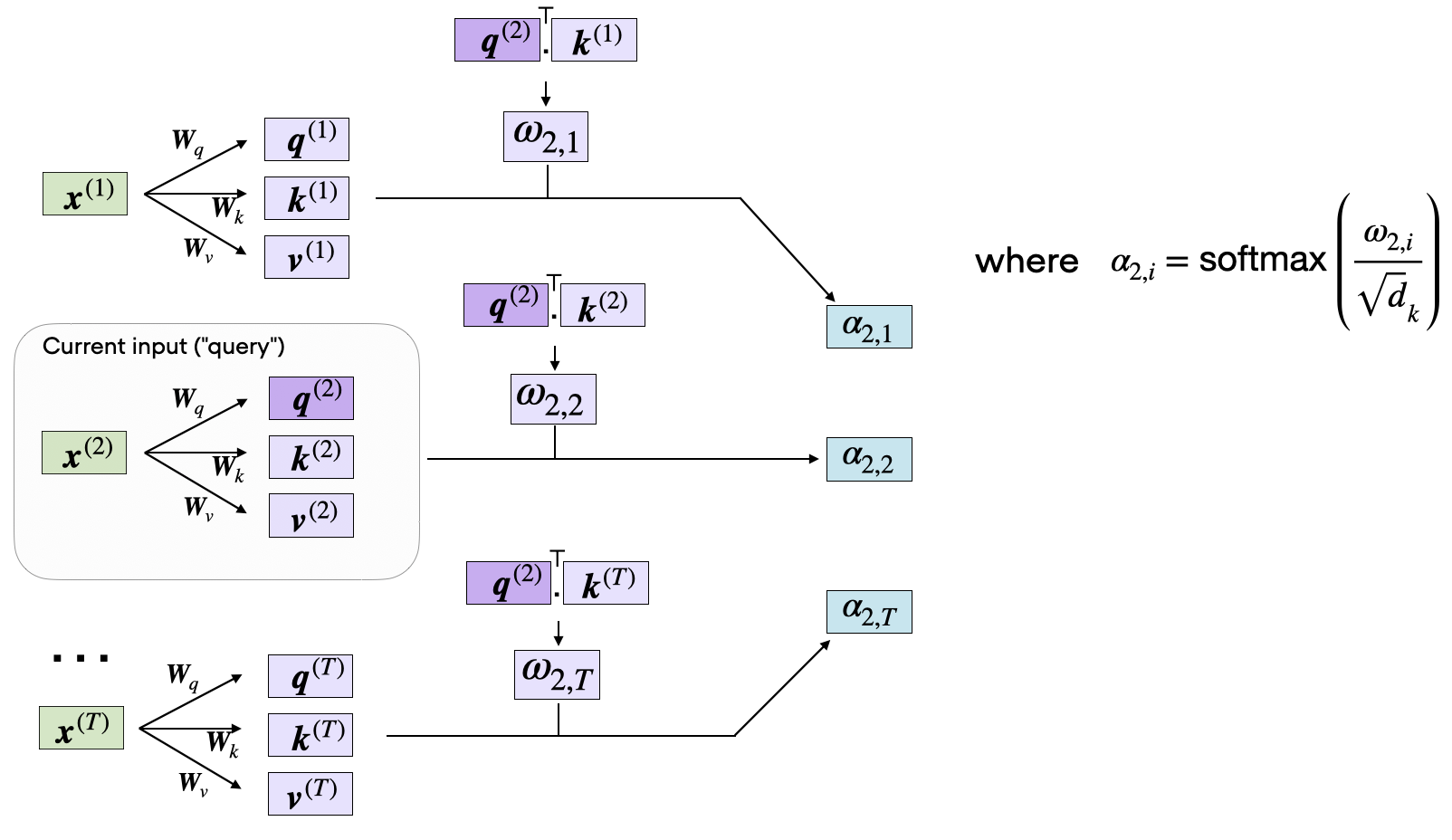
Understanding the attention mechanism in sequence models
Jeremy Jordan explains in this post the attention mechanism using numerous helpful diagrams and an accessible language style. The attention mechanism enables the decoder to search across the entire input sequence for information at each step during the output sequence generation. This is a key innovation in sequence-to-sequence neural network architectures because it significantly improves model performance.
-
This post by Lilian Weng also includes detailed explanations and numerous useful diagrams to understand the attention mechanism.
Understanding and Coding the Self-Attention Mechanism of Large Language Models From Scratch
Here, Sebastian Raschka explains how self-attention works from scratch by coding it step-by-step.
🎥 You can also find valuable information about the attention mechanism in the following videos:
Sebastian Raschka
DeepLearningAI
3Blue1Brown
Tokenization and embeddings#
Tokenization and embeddings are two essential steps in the data processing pipeline of LLMs. Tokens are the fundamental units of LLMs. Tokenization is the process of translating text into sequences of tokens and vice versa, breaking down the text into manageable pieces that the model can interpret. Once the text is tokenized, each token is mapped to an embedding vector. These embeddings are dense, low-dimensional, continuous vector representations that capture the semantic and syntactic meanings of tokens, allowing the model to understand the nuances of language. These vectors are learned during the model’s training process. For more information on tokenization and embeddings, you can explore the resources listed below. (Figure - Tiktokenizer)
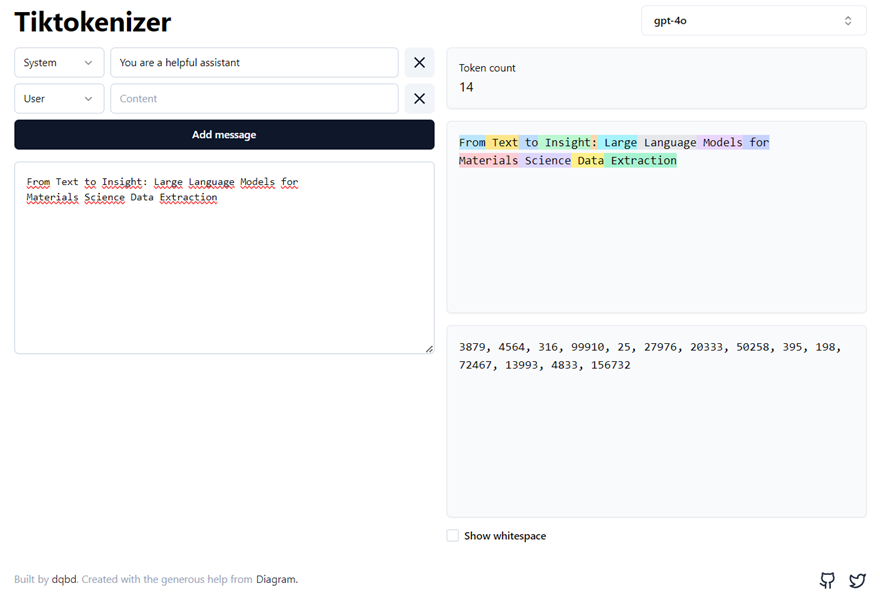
The Technical User’s Introduction to LLM Tokenization
In this post, Christopher Samiullah delves into the mechanics of tokenization in LLMs, referencing Andrej Karpathy’s YouTube talk Let’s build the GPT Tokenizer.
-
If you want to dive deeper into this topic, check out the mentioned talk by Andrej Karpathy, where he builds from scratch the Tokenizer used in the GPT series from OpenAI, highlighting “weird behaviors” and common issues associated with tokenization. He also created
minbpe, a repository with code and exercises for further learning. -
You should check out this link and try tokenization using the Tiktoken web app. With this tool, tokenization runs live in your web browser, allowing you to easily input some text string on the left side and see the tokenized output on the right side in real-time.
What Are Word and Sentence Embeddings?
In this post, Luis Serrano (Cohere) provides a straightforward introduction to embeddings using practical examples.
Model training#
-
The simplest, fastest repository for training/finetuning medium-sized GPTs by Andrej Karpathy. It includes a minimal code implementation of a generative language model for educational purposes.
Building a GPT that can generate molecules from scratch
Here, Kevin M. Jablonka explains how LLMs work through a practical approach applied to chemistry, guiding you on how to build a GPT model that can generate molecules from scratch. It includes a detailed tutorial covering the tokenization process, conversion of tokens into numbers, vector embeddings and positional encoding, as well as model training and evaluation. Through this relatively simple example, you will also learn how the attention mechanism works with an exhaustive implementation of self-attention into the model.
🎥 In this video you can learn how to build a GPT model following the paper “Attention is All You Need”: Let’s build GPT: from scratch, in code, spelled out by Andrej Karpathy.
Prompting#
-
Lilian Weng presents in this blog post everything you need to know about the basics of prompting and some advanced prompt techniques such as Chain of Thought (CoT).
-
Learn prompting webpage has multiple updated resources and one free course on how to prompt GPT models.
🎥 Learn to Spell: Prompt Engineering (LLM Bootcamp) This video shows a basic guide for effectively prompting language models by reviewing prompting techniques, like decomposition, reasoning, and reflection (The Full Stack).
📘 Books#
Natural Language Processing with Transformers (Lewis Tunstall, Leandro von Werra, Thomas Wolf, 2022)
While the overall objective of this book is to show you how to build language applications using the Hugging Face 🤗 Transformers library, it explains the Transformer architecture in a clear and detailed way. Chapter 2, Text Classification, shows how tokenizers work, whereas Chapter 3, Transformer Anatomy, takes a closer look at how transformers work for natural language processing. You will learn about the encoder-decoder architecture, embeddings, and self-attention mechanism. The authors present a hands-on approach, making it easy to read and simple to understand the Transformer architecture.
Generative Deep Learning (David Foster, 2023)
Starting with an introduction to generative modeling and deep learning, this book explores the different techniques to build generative models. In Chapter 9, Transformers, it provides an overview of the Transformer model architecture, attention mechanism, and encoder-decoder architectures.
Understanding Deep Learning (Simon J.D. Prince, 2023)
This book begins by introducing deep learning models and discuss how to train them, measure their performance, and improve this performance. It then presents the architectures that are specialized to images, text, and graph data. Chapter 12, Transformers, explains self-attention and the transformer architecture. This is one of the most educational resources on deep learning available today.